DeepCredit Experiment: Evaluating LLM Performance on Hard CRR Questions
DeepCredit Experiment: Evaluating LLM Performance on Hard CRR Questions
Introduction
This report details our latest DeepCredit experiment, which represents a significant step toward building a general credit risk analysis agent. The experiment involved creating and evaluating a set of 50 challenging Capital Requirements Regulation (CRR) questions to test the capabilities of various large language models in understanding and applying complex financial regulations.
Methodology
Question Generation Process
We developed a systematic approach to create cognitively demanding regulatory questions that would challenge even seasoned financial professionals. The questions were automatically generated using an LLM that reverse-engineered complex regulatory requirements from the CRR text. Our methodology followed these key steps:
-
Define Purpose and Target Difficulty: We targeted skills requiring deep knowledge of CRR II/III own-funds and credit-risk rules, plus the ability to apply them quantitatively. Questions were calibrated to challenge seasoned regulatory-capital practitioners or CFA/FRM holders.
-
Content Mapping: We extracted an article list from CRR and key Delegated Regulations, then flagged “high-leverage” articles that are frequently misunderstood, embed quantitative scalars, or define critical thresholds.
- Question Design Heuristics: We employed several heuristics to generate challenging questions:
- Exploiting exceptions to general rules
- Requiring precise arithmetic calculations
- Mixing temporal considerations with rule applications
- Cross-referencing different regulatory artifacts
- Incorporating real-world financial instruments
-
Filtering and Validation: We removed duplicates, ensured uniqueness of concepts, and verified that all numerical values traced directly to the regulation.
- Question Formalization: Each question was structured with a consistent schema:
{ "question": <plain language case>, "answer": <precise value or phrase>, "tags": [taxonomy], "references": "Legal pin-cite(s)", "rationale": "One-paragraph proof" } - Quality Control: All questions underwent initial review and self-consistency checks to ensure accuracy and clarity. The evals have not been peer-reviewed yet, but the final set for the benchmark will undergo double peer review.
Example Questions
To illustrate the challenging nature of the questions, here are three examples from the dataset:
Example 1: AT1 Capital Trigger Thresholds
{
"question": "CRR requires AT1 instruments to include a trigger for conversion/write-down when CET1 falls below a level. What is the minimum trigger?",
"answer": "5.13%",
"tags": ["HEXC", "NUMC"],
"references": "CRR Art 54(1)(a)",
"rationale": "Article 54(1)(a) specifies that AT1 instruments must have provisions requiring the principal amount to be written down upon the Common Equity Tier 1 capital ratio falling below 5.125%."
}
Example 2: Significant Investment Threshold Deductions
{
"question": "Bank JKL holds a 12% stake in another financial institution (significant investment in CET1 of a financial sector entity) amounting to €50 million. Bank JKL's own CET1 capital is €400 million. Under the threshold regime, how much of this €50 million must be deducted from CET1?",
"answer": "€10 m",
"tags": ["NUMC", "DMAT"],
"references": "CRR Art 48(1)",
"rationale": "According to Article 48(1), significant investments in financial sector entities are subject to the 10% threshold. The threshold amount is 10% of Bank JKL's CET1 (€400m × 10% = €40m). Since the investment exceeds this by €10m (€50m - €40m), that excess amount must be deducted from CET1."
}
Example 3: Capital Instrument Eligibility
{
"question": "A bank issued perpetual bonds that are deeply subordinated, but their coupons are cumulative (missed payments accumulate as liabilities). Under CRR own-funds rules, how much of this instrument can count toward regulatory capital?",
"answer": "0",
"tags": ["HEXC", "TREE"],
"references": "CRR Art 52(1)(l)",
"rationale": "Article 52(1)(l) explicitly requires AT1 instruments to have distributions that are paid only out of distributable items and the institution has full discretion to cancel distributions at any time. The accumulation of missed payments as liabilities (cumulative coupons) contradicts this requirement, making the instrument ineligible for AT1 capital."
}
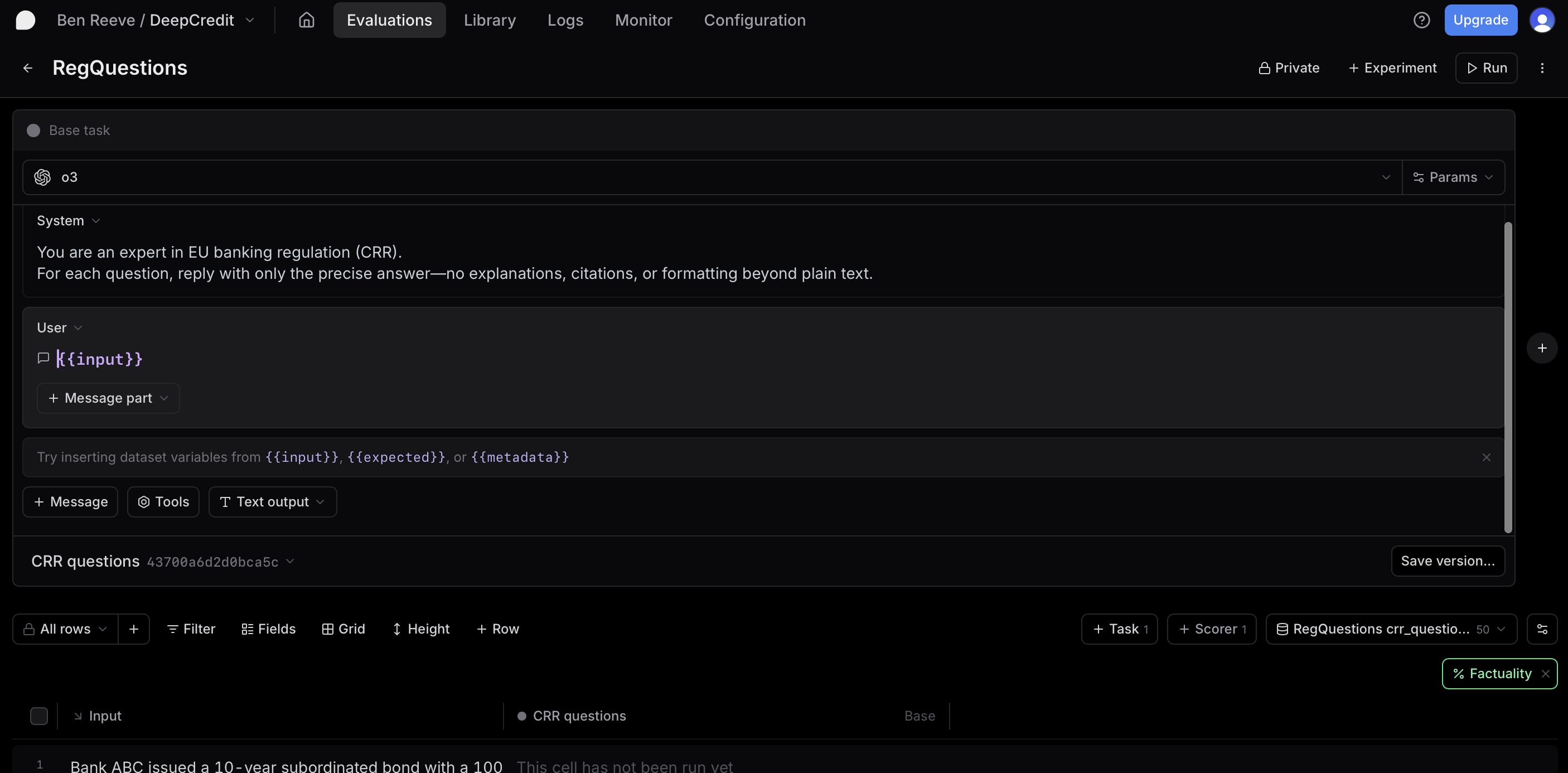
Evaluation Setup
The evaluation was conducted using braintrust.dev, a specialized evaluation platform that allows for easy setup of language model assessments. We selected braintrust.dev for its ability to run evaluations without code by simply uploading datasets as CSV files and configuring system prompts within the app.
We tested four OpenAI models (using the latest versions as of May 13, 2025):
- o3 - The largest reasoning-optimized model
- o3-mini - A distilled, more efficient version of o3
- GPT-4o (4o) - The standard non-reasoning model
- GPT-4o-mini (4o-mini) - A distilled smaller version of 4o
The evaluation used a “Factuality” scoring method to assess the correctness of model responses against the expected answers.
Results Summary
Our evaluation revealed significant performance differences across models, with GPT-3.5-turbo (o3) demonstrating a substantial performance uplift compared to other models. However, analysis of the scores indicated that the “Factuality” scoring method was sometimes overly strict, understating the performance of models that provided technically correct answers but with minor formatting differences.
Performance by Model
| Model | Factuality Score |
|---|---|
| o3 | 77.20% |
| GPT-4o (4o) | 56.80% |
| GPT-4o-mini (4o-mini) | 47.60% |
| o3-mini | 47.20% |
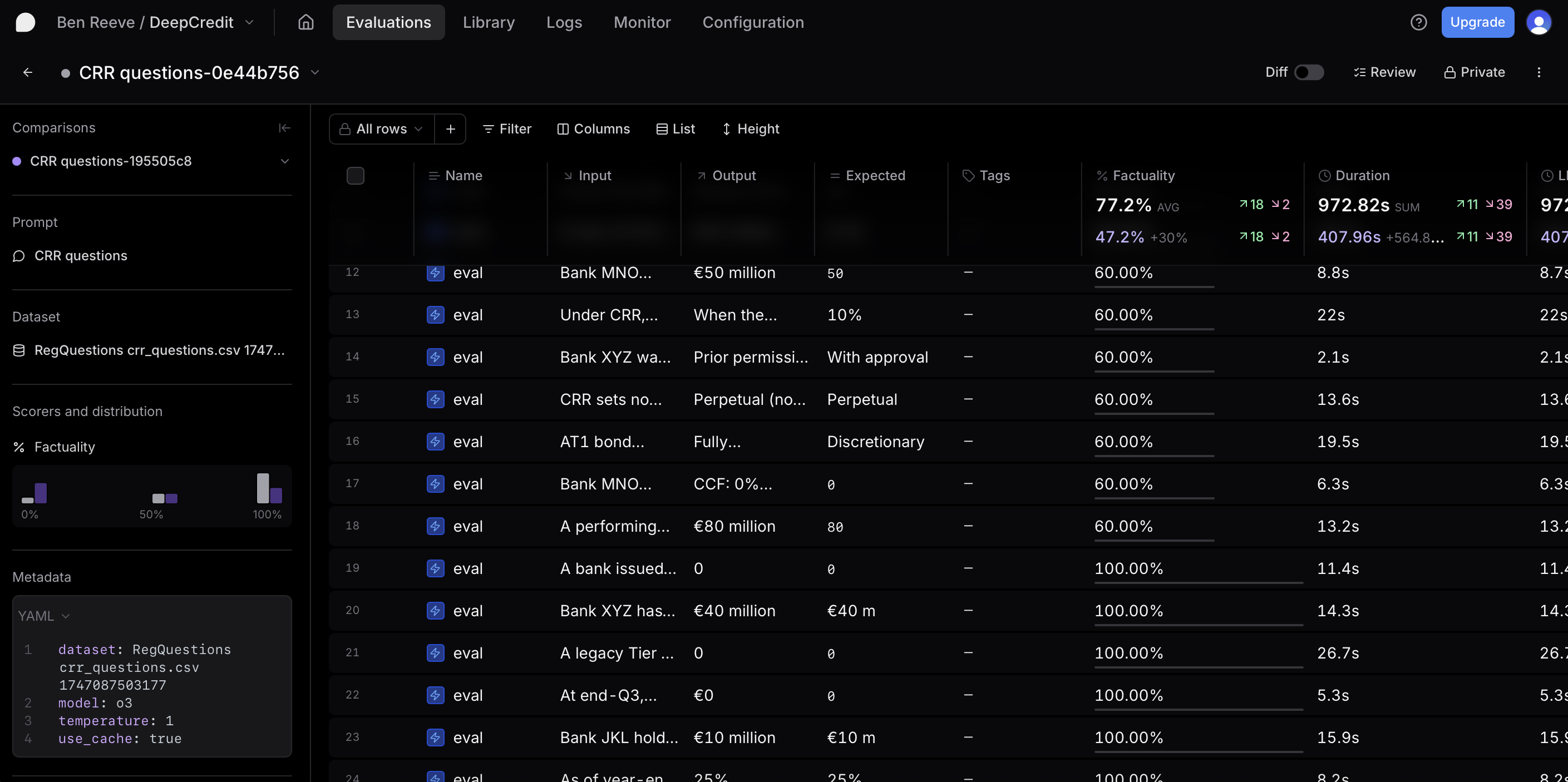
The performance ranking reveals an interesting pattern. Conceptually, one would expect the performance to follow the model capability hierarchy (o3 > o3-mini > 4o > 4o-mini), since o3 is the most advanced reasoning-optimized model, followed by its distilled version (o3-mini), then the standard non-reasoning model (4o), and finally its smaller variant (4o-mini).
However, o3-mini underperformed, scoring even below 4o-mini, which is theoretically the least capable model in the set. This result represents another step in our understanding of model performance and highlights the importance of empirical evaluation for assessing model capabilities in specialized domains. The strong performance of o3 confirms its suitability for this type of agent, while raising questions about the effectiveness of the distillation process for regulatory knowledge in o3-mini.
Analysis of Model Performance
Real Failure Patterns
Analyzing the results revealed several substantive patterns where models genuinely struggled with regulatory knowledge and reasoning:
-
Regulatory threshold misunderstandings: Smaller models particularly struggled with precise regulatory thresholds and their applications. For example, several models incorrectly applied the threshold for significant investments in financial entities.
-
Complex calculation errors: Questions requiring multi-step calculations involving regulatory factors showed higher failure rates in smaller models. This was particularly evident in questions involving the SME supporting factor, risk-weighted assets calculations, and minority interest calculations.
-
Capital instrument classification errors: Some models failed to correctly identify the eligibility criteria for various capital instruments, especially in edge cases like perpetual bonds with cumulative coupons.
-
Risk weight application inconsistency: Models frequently applied incorrect risk weights to exposures, especially when dealing with special cases like currency mismatches or specific counterparty types.
Scoring Mechanism Limitations
The evaluation also revealed important limitations in the scoring methodology that need to be addressed:
-
Currency formatting variations: Many models provided numerically correct answers but received reduced scores due to formatting differences (e.g., “€40 million” vs “€40 m” vs “40m euros”). These are not genuine knowledge failures but scoring artifacts.
-
Percentage formatting inconsistencies: Differences in percentage formatting (e.g., “5.125%” vs “5.13%”) led to score reductions despite conceptual correctness.
-
Verbosity penalties: Some models provided correct answers but embedded them in longer explanations, resulting in partial scores rather than full credit.
These scoring issues suggest the need for developing a custom scoring method that can properly evaluate conceptual correctness while accommodating reasonable variations in answer formatting and presentation.
Examples of Substantive Model Failures
The evaluation revealed several examples where models demonstrated genuine conceptual misunderstandings of regulatory requirements, as opposed to merely formatting or verbosity issues:
Example 1: Misunderstanding Threshold Deduction Rules
Question: “Bank JKL holds a 12% stake in another financial institution (significant investment in CET1 of a financial sector entity) amounting to €50 million. Bank JKL’s own CET1 capital is €400 million. Under the threshold regime, how much of this €50 million must be deducted from CET1?”
Expected Answer: “€10 m”
Key Finding: 4o-mini completely misunderstood the threshold deduction mechanism, answering “€0 million” when the correct amount was €10 million. This demonstrates a fundamental failure to grasp how the 10% threshold applies to significant investments in financial entities. Both 4o and o3 correctly calculated the €10 million deduction.
Example 2: Incorrect AT1 Capital Eligibility Assessment
Question: “A bank issued perpetual bonds that are deeply subordinated, but their coupons are cumulative (missed payments accumulate as liabilities). Under CRR own-funds rules, how much of this instrument can count toward regulatory capital?”
Expected Answer: “0”
Key Finding: 4o-mini incorrectly claimed that “100% of the instrument can count toward regulatory capital as Additional Tier 1 (AT1) capital,” revealing a complete misunderstanding of one of the fundamental eligibility criteria for AT1 capital instruments. Cumulative coupons are explicitly disqualified under CRR regulations. Both 4o and o3-mini correctly identified that the instrument didn’t qualify, while o3 provided the most concise answer.
Example 3: Infrastructure Supporting Factor Miscalculation
Question: “A project-finance loan meets all conditions for the infrastructure supporting factor (base RW 100%). What risk weight applies?”
Expected Answer: “75%”
Key Finding: Multiple models provided incorrect risk weights, with o3-mini answering “80%” and 4o-mini answering “50%”, while the correct answer according to CRR is 75%. This shows a failure to correctly apply the specific supporting factor defined in the regulation.
Example 4: SME Supporting Factor Application
Question: “A performing SME loan of €3 million is subject to the SME supporting factor (base RW 100%). What RWA results after the factor?”
Expected Answer: “€2.33 m”
Key Finding: Both smaller models produced incorrect calculations, with 4o-mini answering “€1.5 million” and o3-mini answering “€2,400,000”, neither of which corresponds to the correct application of the 0.7619 SME supporting factor. This demonstrates difficulties with the precise quantitative applications of regulatory adjustments.
Insights and Implications
Evaluation Methodology Considerations
The experiment highlighted important considerations for future evaluations:
- Developing custom scoring methods: The standard “Factuality” scoring method frequently penalized technically correct answers due to minor formatting differences, significantly underestimating model performance. For future evaluations, we need to develop a custom scoring approach that:
- Normalizes numerical answers before comparison (e.g., converting “€10m”, “€10 million”, “10 million euros” to a standard format)
- Recognizes acceptable variations in percentage precision (e.g., 5.125% vs 5.13%)
- Extracts key answers from longer explanations when models provide additional context
- Implements regex-based matching rather than exact string comparison
-
Answer standardization: Expected answers should be formalized with clear guidelines for acceptable variations to ensure consistent scoring across different response formats.
-
Manual verification pipeline: Some evaluation discrepancies require human judgment to properly assess, especially when dealing with complex regulatory concepts where multiple formulations of an answer might be correct. A systematic human review process should be implemented for borderline cases.
- Two-phase scoring: Consider implementing a two-phase scoring approach where basic correctness is evaluated first, followed by assessment of precision and conciseness as secondary factors.
LLM Performance on Regulatory Questions
Our findings suggest several important insights about LLM capabilities in the regulatory domain:
-
Model capability vs. empirical performance: The results demonstrate a divergence between theoretical model capabilities and empirical performance on specialized regulatory tasks. Despite o3 being designed as a reasoning-optimized model and performing well (77.20%), its distilled counterpart o3-mini performed more modestly (47.20%), even slightly underperforming the theoretically less capable 4o-mini model (47.60%).
-
Reasoning mechanism effectiveness: The strong performance of o3 suggests that its reasoning mechanisms are effective for navigating the complex, multi-step calculations and logical applications required by CRR regulations. However, these reasoning capabilities appear to be less preserved in the distillation process for o3-mini.
-
Knowledge representation differences: Models appear to differ in how they represent and access regulatory knowledge, with certain architectures potentially preserving regulatory expertise better than others through different training or optimization approaches.
Future Directions
Based on the insights from this experiment, we’ve identified several promising directions for the DeepCredit project:
-
Expanded question set: Develop a more comprehensive set of regulatory questions spanning additional aspects of credit risk regulations, including Basel III, IFRS 9, and stress testing frameworks.
-
Fine-tuned evaluation methods: Refine scoring methods to better assess conceptual understanding rather than exact string matching, potentially incorporating rubric-based evaluation approaches.
-
Model specialization: Explore the potential for fine-tuning specialized models on regulatory texts to enhance performance on complex financial regulatory tasks.
-
Multi-step reasoning: Design evaluations that explicitly test models’ abilities to perform multi-step reasoning in regulatory contexts, tracking intermediate calculation steps.
-
Integration with retrieval: Evaluate how retrieval augmentation might further enhance model performance by providing direct access to regulatory documents.
-
Cost-performance analysis: Further investigate the surprising performance differences between models of different sizes and architectures to optimize the cost-performance trade-off for regulatory applications.
-
Prompt engineering and fine-tuning: Given that o3 achieved its strong performance without any prompt engineering or fine-tuning, explore how specialized prompting techniques and targeted fine-tuning on regulatory texts could further enhance performance.
Conclusion
The DeepCredit experiment with 50 hard CRR questions has provided valuable insights into the capabilities and limitations of current language models in understanding and applying complex financial regulations. The significant performance uplift demonstrated by o3 suggests that we are approaching a threshold where LLMs can provide meaningful assistance with complex regulatory compliance tasks.
Notably, o3 achieved its strong performance (77.20%) without any prompt engineering or fine-tuning specifically for regulatory tasks. This “out-of-the-box” performance is encouraging and suggests substantial room for further improvement through specialized optimization techniques.
This experiment serves as an important foundation for our broader goal of building a general credit risk analysis agent, highlighting both the promise and the challenges of applying LLMs to highly specialized regulatory domains. The methodology developed for creating challenging regulatory questions provides a valuable template for expanding our evaluation framework to cover additional aspects of credit risk analysis.
Beyond evaluation, this question generation methodology will directly feed into the development of our proprietary credit risk benchmark. In the longer term, these synthetic question datasets may serve as the foundation for reinforcement fine-tuning approaches, where models can learn to answer challenging regulatory questions by practicing and receiving feedback on the correctness of their responses. This represents a promising path toward LLMs that can consistently navigate the intricacies of financial regulation with high accuracy.