Knowledge Companies Can't Just Build Their Own ChatGPT
Knowledge Companies Can’t Just Build Their Own ChatGPT
The thing about modern artificial intelligence is that it’s technically two things: there’s the raw intelligence part (the “large language model” or LLM), and then there’s the alignment part (making it actually do what humans want). This distinction matters quite a bit if you’re any knowledge economy company—a law firm, financial services provider, research organization, or professional services firm—thinking about building your own AI tools to compete with the likes of OpenAI, Anthropic or Google. The raw intelligence might be accessible, but the alignment—the part that makes AI tools actually useful—turns out to be astonishingly expensive.1
The Alignment Tax
Consider what Meta did with their LLaMA-2 chatbot. They spent something like $20-25 million just collecting human preference data—people saying “this response is better than that one”—to train their model to be helpful and not, you know, accidentally advise clients to try an exciting new tax strategy called “fraud.” This doesn’t include the hundreds of millions they spent on the base model training or the engineering talent. Meta calls this the “alignment tax,” which I love because it perfectly captures the grudging necessity of it all.2
This creates a kind of AI inequality that works exactly like financial inequality. The ultra-wealthy (in AI terms) have alignment strategies unavailable to the merely affluent. If you’re OpenAI, you can spend $100 million training GPT-4 and test 50 different versions before selecting a final candidate. Each of those test versions probably costs more than your entire law firm’s annual technology budget.
“But wait,” I hear you say, “Stanford researchers built Alpaca for only $600! Surely we can do something similar?” This is like saying “Warren Buffett started with a paper route, so I can definitely become a billionaire investor.” The $600 experiment was essentially having OpenAI’s models teach a smaller model how to behave. The results were, predictably, visibly worse than the teacher. Your clients, who are already using ChatGPT to draft initial contracts or analyze financial statements, will immediately notice the difference.
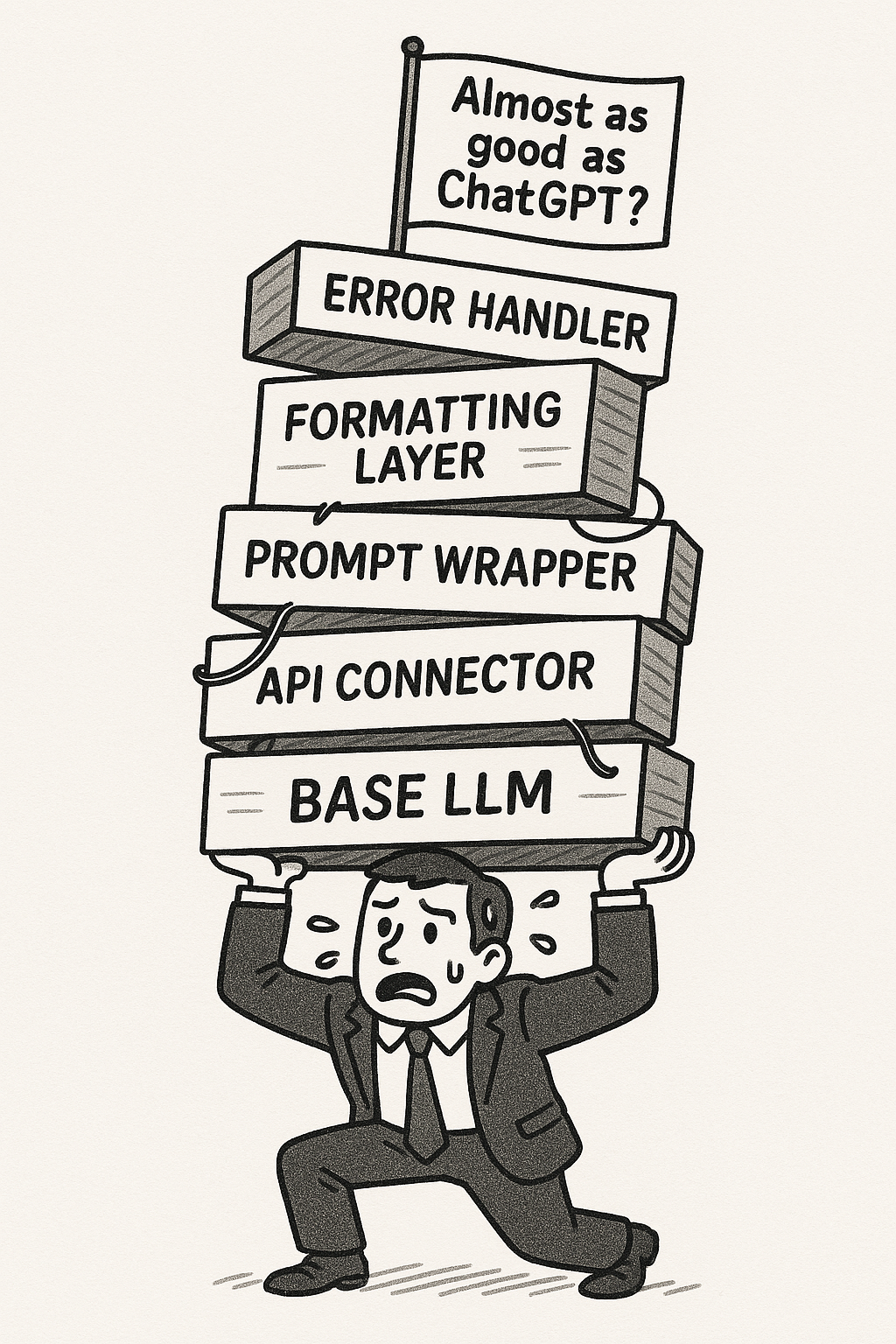
The Tool Problem Is Even Worse
But here’s the really important part that’s easy to miss: When we talk about ChatGPT, we’re not just talking about GPT-4 as a standalone model. We’re talking about GPT-4 that has been specifically RL-trained to seamlessly integrate with tools—to know when to use a calculator, when to search the web, when to generate an image, and how to synthesize information.
This isn’t something you can replicate by writing some Python code to connect APIs. The model has been trained through reinforcement learning to understand how to use these tools effectively.
Take OpenAI’s research capabilities. They haven’t just connected their model to Google and called it a day. They’ve used reinforcement learning from human feedback to teach the model how to research: when to go deeper on a particular source, when to triangulate perspectives, when to dismiss an initially promising lead.
This is the difference between giving a Bloomberg terminal to a first-year analyst versus a 30-year market veteran. Same interface, entirely different results.
Knowledge Work in the AI Age
The professional services industry—law, finance, consulting, research—has long sold itself on having proprietary tools and methodologies. “Our unique analytical framework” is practically a required phrase in pitch decks. This has always been somewhat fictional—most professionals know the real value is in the people and the application of knowledge—but the fiction was sustainable because clients couldn’t easily access alternatives.
That’s changing. When your client can pay $20/month for ChatGPT Plus and get better legal research than your cobbled-together system produces, the premium positioning crumbles. It’s like finding out your hedge fund’s proprietary trading algorithm is actually just “buy tech stocks and charge 2 and 20.”
Consider what happens when a client asks a complex legal question. OpenAI’s system might invisibly:
- Recognize knowledge gaps and seamlessly search for relevant case law
- Identify precedents warranting deeper exploration
- Pull data from multiple formats (legal databases, PDFs, tables)
- Synthesize contradictory rulings to provide a balanced analysis
Your in-house system, meanwhile, will visibly struggle with transitions between these phases, often returning analysis that looks suspiciously like “we searched Westlaw and summarized the first page of results.”
The same applies to financial analysis. A bank’s proprietary AI might promise sophisticated market insights, but if it’s noticeably worse than what a client can access through a commercial API, the premium mystique evaporates.
The Three Options
Knowledge economy companies essentially have three options:
1. Partner with the leaders. Accept that building competitive AI tools requires resources beyond even large professional services firms, and negotiate special access to leading platforms. “We’ve integrated OpenAI’s technology with our proprietary data” isn’t as impressive as “we built our own AI,” but it’s better than “our AI is noticeably worse than what you’re already using.”
2. Focus on proprietary data. The one area where firms might maintain advantage is in combining AI with truly proprietary data and frameworks. If you have exclusive data that general models can’t access, that’s valuable. This is why financial firms are frantically digitizing their historical trading data and law firms are racing to structure their case archives.
3. Reframe the value proposition. Perhaps the premium isn’t in having better AI tools, but in having humans who know exactly when to use them and when to override them. This is the “AI whisperers” approach—we don’t have better hammers, but we have better carpenters.
The third option is probably the most realistic but requires a significant ego adjustment for firms that have traditionally positioned themselves as technology leaders. It’s hard to charge premium rates while admitting “we use the same tools as everyone else, just more skillfully.”
The Compounding Problem
In a particularly cruel twist, this dynamic compounds over time. Every interaction with these RL-trained systems generates more training data to make them better. The models aren’t static—they’re constantly learning and improving.
Meanwhile, your static, manually-programmed tooling remains frozen at its initial capability level. The gap with state-of-the-art continuously widens, much like compound interest working against someone trying to catch up to the already-wealthy. By the time you’ve built something comparable to GPT-4’s capabilities, they’ll be on GPT-6.
This creates a kind of Darwinian pressure on knowledge work itself. Tasks that can be easily automated migrate to AI, while human professionals concentrate on work that resists automation—managing client relationships, handling novel situations, navigating ambiguity, and providing judgment.
Why This Matters
This has broader implications for how value is created and captured in the knowledge economy. We’re seeing a pattern where companies with the resources to pay the “alignment tax” are capturing disproportionate value, while traditional knowledge firms are relegated to being implementation partners or value-added resellers.
The knowledge economy companies that will thrive aren’t those building second-rate AI tools, but those who most quickly adapt to a world where the best AI tools are widely available—and find ways to create value around them rather than competing with them.
The alternative—pretending your homegrown AI is competitive when clients can directly compare it to ChatGPT—is a bit like claiming your in-house search engine is better than Google. It’s theoretically possible, but extraordinarily unlikely, and making the claim damages your credibility on everything else.
In the end, the knowledge economy isn’t being replaced by AI—it’s being reshaped by it. The value is shifting from information processing to judgment, from computation to wisdom, from tool-building to tool-wielding. That’s a much more profound change than simply adding AI to the existing business model, and it requires rethinking what knowledge work actually is.
-
Large language models are basically systems trained to predict the next word in a sequence. Technically impressive, but left to their own devices, they’ll happily suggest that the SEC requires disclosure of executive astrological signs in 10-Ks. Alignment is the process of making them not do that. ↩
-
Meta reportedly estimated their preference data collection alone cost millions. One analyst described it as the “cherry on top” that makes the model usable, but what a cherry—costing roughly 100,000 times more than the actual cherries you’d put on an ice cream sundae. ↩